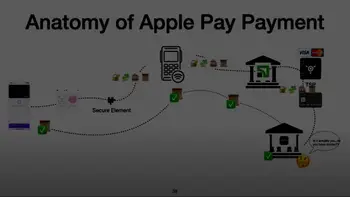
The world is full of data, lots of data: images, music, words, videos. Machine learning, processing these data, can get a specific answer and result from them. That is, it is a tool and a technology that you can use to answer questions with your data.
Today, there is a lot of data in the world, created not only by people but also by computers, phones, and other devices. These data are used in various spheres of life. Already, the volume of such data exceeds the ability of people to process it on their own, so we are increasingly turning to automated systems that can learn from data and significantly change data to, for example, somehow adapt it.
We see machine learning all around us in the products we use today. It can be pretty obvious things, such as, for example, object recognition, directly using our phone. Sometimes, it gives the expected and predictable result, sometimes not. What takes us a fraction of a second to correctly recognize can be a difficult task for a recognition system, for example, due to a lack of relevant data.
It is not always obvious what is behind machine learning and what is not. Perhaps the biggest example of all is Google Search. Every time we use search, we use a system that is based on many machine learning systems. This may include systems to understand query text and adjust results based on our interests and past queries. This shapes what results to show us first.
That is, if you shorten the definition of machine learning, it is the use of data to get answers to questions. The two parts of this sentence, “using data” and “answering questions”, broadly describe two sides of machine learning, which are equally important. Using the data is what is called learning, and the answers to the questions are predictions or inferences.
To train a model, we need to collect data for training. Data collection is essential because the quality and quantity of data will directly determine how good your model can be.
The next step in machine learning is data preparation — we prepare it for use in training. We combine all our data and arrange it randomly. This is an excellent time to see if there are relevant relationships between different variables, and it will also show if there are any imbalances in the data. We also need to split the data into two parts. The first part is used to train the model, which is most of our dataset. The second part will be used to evaluate the model's effectiveness — testing.
The learning process involves initializing some random weight values for the input data and then trying to predict the output data based on that. Of course, it works pretty poorly at first, but here we also compare the model's predictions to the actual response it should have produced, and then we adjust the weights so that we have more accurate predictions next time. Therefore, this process is repeated. When we first start learning, it's like we draw a random line through the data. As each stage of learning progresses, the line moves step by step closer to perfect separation.
Testing allows us to test our model on data never used for training. This metric allows us to see how the model can perform with data it hasn't seen before. After we have made this assessment, it is possible to see if you can improve the training in some way: adjust the parameters, weights, how many times to pass through the data, and so on.
TensorFlow's Object Detection API makes machine learning simple and accessible. This is the basis for building your deep-learning network if you need to solve the object detection problem. In the structure of this framework, there are already pre-prepared and trained models, which are called Model Zoo. As more data is collected, the models can be refined over time, and new models can be deployed. A vital component of this whole process is data. It all depends on the data.